Advanced RAG Cooking Guide & Techniques
How to build your own RAG with standard
👨🏾💻 LinkedIn ⭐️| 🐦 ViliminAi | ❤️Vilimin.com

In simple, What is simple RAG?
The prevailing concept of RAG, as presently articulated, entails fetching documents from an external knowledge database. Subsequently, these documents, along with the user’s query, are transmitted to an LLM for the generation of responses. In essence, RAG encompasses a Retrieval component, an External Knowledge database, and a Generation component.

In a simplified RAG scenario, the process involves dividing texts into segments, embedding these segments into vectors using a Transformer Encoder model, placing these vectors into an index, and ultimately generating a prompt for an LLM. This prompt instructs the model to respond to the user’s query based on the context discovered during the search phase.
Why Advanced RAG?
Once the well defined requirements are outlined, constructing an advanced RAG involves implementing more sophisticated techniques and strategies, either in the Retrieval or Generation components. This ensures the fulfillment of these requirements. Additionally, sophisticated techniques can be categorized as those addressing one of the two high-level success requirements independently, or those simultaneously addressing both requirements.
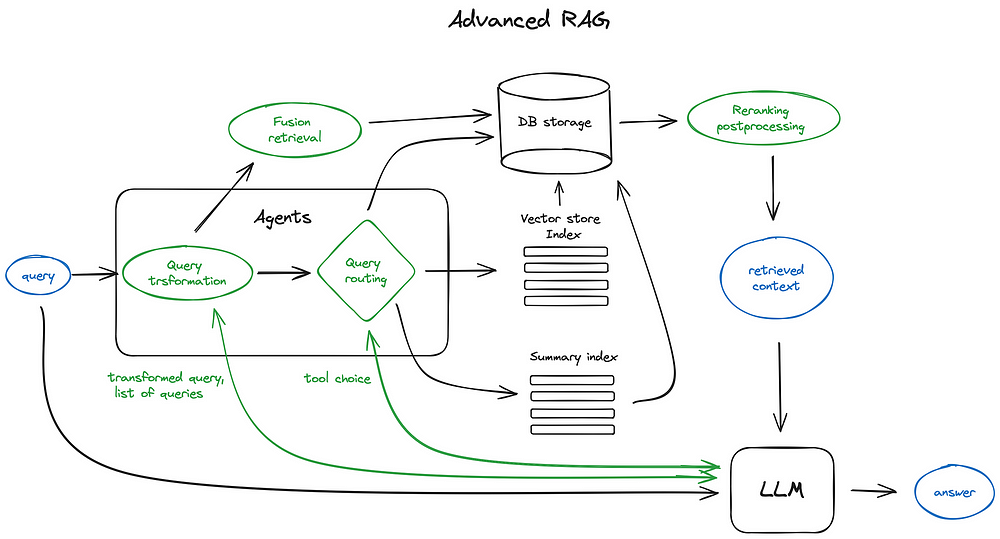
📚 Here are the key takeaways
Advanced RAG (Retrieval-Augmented Generation) techniques. It covers:
➡️ Motivation for Building Advanced RAG Systems
➡️ Basic RAG Systems
➡️ Advanced RAG Systems
➡️ Key Abilities and Quality Scores of Advanced RAG Systems
➡️ Building External Knowledge Steps
🔍 Basic RAG: It involves retrieving documents from an external knowledge database and passing these along with the user’s query to an LLM for response generation. The main components are a Retrieval component, an External Knowledge database, and a Generation component.
🌐 Success Requirements for RAG: A successful RAG system should have two primary capabilities: Retrieval must find the most relevant documents to a user query, and Generation must utilize these documents effectively to answer the user query.
💡 Advanced RAG: Building an advanced RAG involves applying more sophisticated techniques and strategies to meet the success requirements. These techniques can either address one of the high-level success requirements independently or both simultaneously.
🎯 Advanced Techniques for Retrieval: This includes performing hyperparameter tuning via grid-search, and structuring external knowledge for recursive or routed retrieval.
🖥️ Advanced Techniques for Generation: This includes making good use of the retrieved documents, re-ranking the results, and using Information Compression to reduce noise.
🤝 Advanced Techniques for Simultaneously Addressing Retrieval and Generation: This includes Generator-Enhanced Retrieval and Iterative Retrieval-Generator RAG.
People who interested to read more keep continue further:
The RAG Framework Basics
As the realm of AI applications broadens, the requirements for RAG are growing increasingly intricate and diverse. The foundational RAG framework, though resilient, may no longer suffice to meet the nuanced demands of various industries and evolving use cases. This is where advanced RAG techniques take center stage. These refined methods are designed to address specific challenges, providing heightened precision, adaptability, and efficiency in information processing.
At a high level, RAG systems contain three key modules:
- Retriever — retrieves passages of text from a knowledge source that are relevant to the context
- Reranker (optional) — rescores and reranks retrieved passages
- Generator — integrates context with retrieved passages to generate output text
- Data preparation: It begins with the user uploading data, which is then ‘chunked’ and stored with embeddings, establishing a foundation for retrieval.
- Retrieval: Once a question is posed, the system employs vector search techniques to mine through the stored data, pinpointing relevant information.
- LLM query: The retrieved information is then used to provide context for the Language Model (LLM), which prepares the final prompt by melding the context with the question. The result is an answer generated based on the rich, contextualized data provided, demonstrating RAG’s ability to produce reliable, informed responses.
The High level flow

The retriever locates pertinent passages from the knowledge source, considering the context. Optionally, the reranker scores and reorders these passages. Subsequently, the generator utilizes both the context and retrieved passages to produce output text enriched with external knowledge.
RAG systems capitalize on external textual knowledge to elevate language generation, drawing from sources like Wikipedia articles, news archives, or domain-specific corpora.
Conditioning generations on retrieved evidence minimizes hallucinations, enhances question-answering accuracy, and results in more informative and relevant text. The outputs are thus augmented with external knowledge.
Instead of going into more deep, just keeping only main data flow points which relevant to this topic.
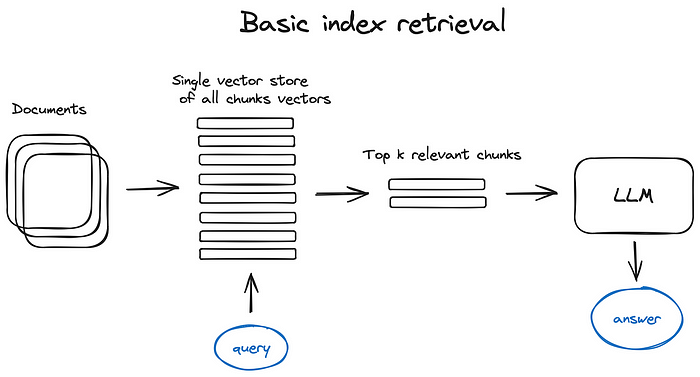
Basic Index
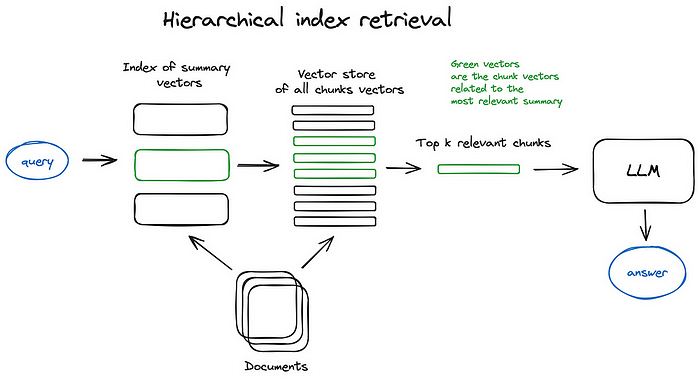
Hierarchical index
Sentence Window Retrieval

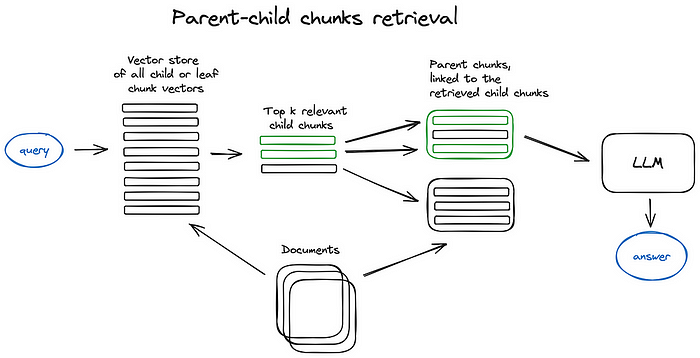
Parent Document Retriever
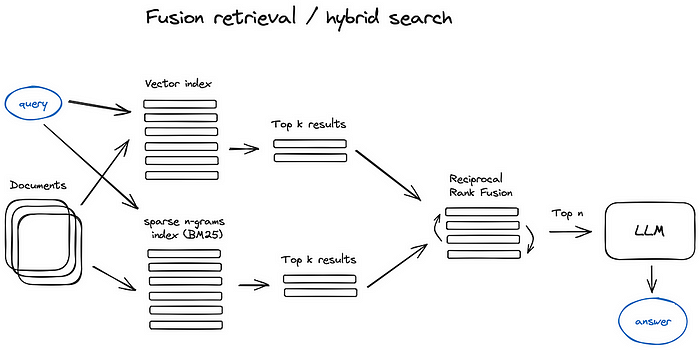
Fusion retrieval
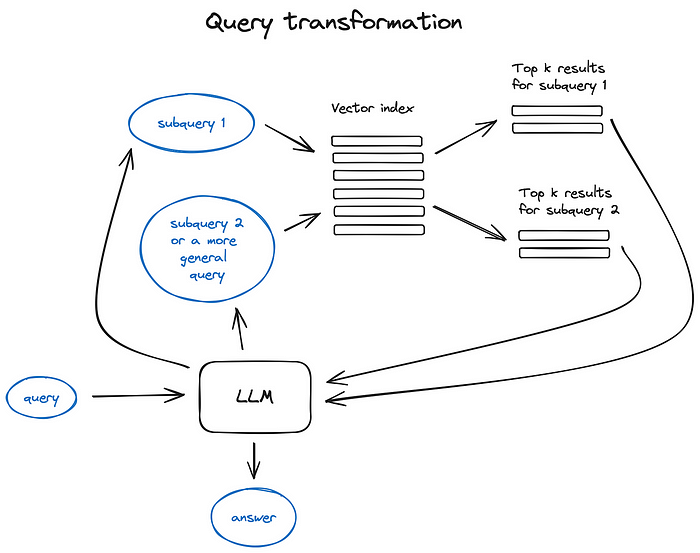
Query transformations
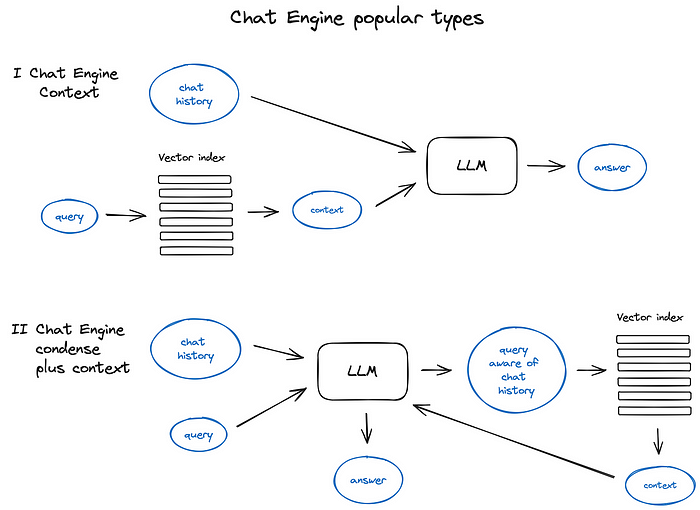
Chat Engine retrieval
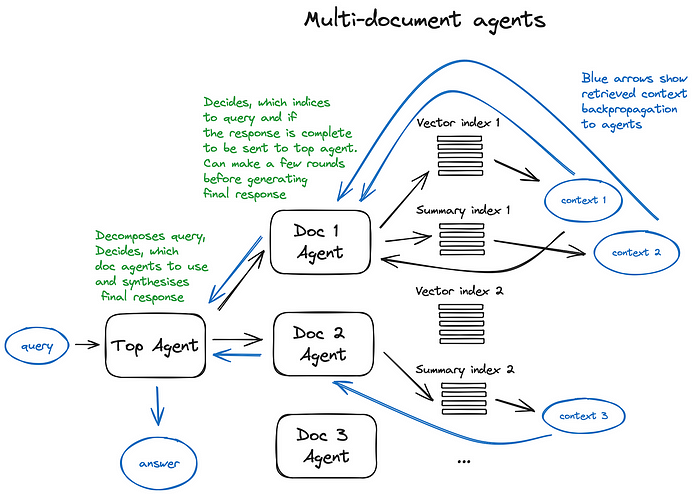
Multi-document retrieval
Key Takeaways
Advanced RAG techniques for LLMs:
- RAG enhances language models by integrating external knowledge retrievals, thereby improving generation accuracy, relevance, and information coverage.
- Retriever advancements elevate lexical, semantic, and contextual relevance matching signals for both long-form and keyword queries.
- Reranker architectures specialize in precisely predicting relevance, employing strategies that combine pretraining, model sizes, and network architectures.
- Generators seamlessly incorporate external evidence through truncation, distillation, weighting, working memory, and entity grounding techniques.
- Hybrid RAG systems combine both LLMs to maximize quality and efficient SLMs for scalability and throughput.
Next…..
As explored, a range of techniques is applied across retrieval, ranking, and generation modules, showcasing adjustments for both network scale and architecture. Through the integration of advancements in query understanding, evidence selection, contextual integration, and output generation, contemporary RAG yields exceptionally robust outcomes, unlocking the external knowledge essential for fueling next-generation applications.
Whether it involves refining the precision of search engines, elevating the pertinence of chatbot responses, or pushing the boundaries of knowledge-based systems, Advanced RAG signifies the continual evolution and sophistication in AI-driven language understanding and information processing. The integration of retrieval accuracy and contextual generation in Advanced RAG sets the stage for more intelligent, responsive, and knowledgeable systems across diverse applications, marking the onset of a new era in AI capabilities.
Hope that you now feel better prepared and confident to implement some of these advanced techniques when constructing RAG systems!
Please connect through 👨🏾💻 LinkedIn for further development.
